Rédigé et vérifié par un professeur diplômé de l’École Polytechnique, avec un niveau de rigueur pensé pour le lycée et la prépa. Découvrir le professeur
Deux séries de données peuvent avoir la même moyenne, mais des valeurs très différentes. L’écart-type est l’outil mathématique qui mesure cette dispersion autour de la moyenne. Incontournable en statistiques dès la Seconde, puis en probabilités avec les variables aléatoires en Terminale et en prépa, c’est un indicateur que tu retrouveras dans chaque chapitre de mathématiques. Tu trouveras ici la définition complète, toutes les formules, une méthode de calcul pas à pas et 6 exercices corrigés.
📚 Tout le cours « Variables Aléatoires »
- 📖 Variable aléatoire : cours complet
- → Espérance
- → Variance
- → Écart-type (cette page)
- → Loi binomiale
- → Loi normale
- → Table de la loi normale
- → Loi de Poisson
- → Loi uniforme
- → Loi exponentielle
- → Fonction de répartition et densité
- → Loi géométrique
- ✏️ Exercices loi binomiale
- ✏️ Exercices variables aléatoires
Accès rapide
- Toutes les formules (stats, proba, König-Huygens)
- Méthode de calcul pas à pas
- Propriétés et interprétation (règle 68-95-99,7)
- 6 exercices corrigés (★ à ★★★)
- Questions fréquentes
I. Définition de l’écart-type
A. Définition intuitive et formelle
Imagine deux classes qui obtiennent la même moyenne de 12/20 à un contrôle :
- Classe A : notes 11 ; 12 ; 12 ; 13 ; 12 — tout le monde est proche de 12.
- Classe B : notes 4 ; 8 ; 15 ; 18 ; 15 — les résultats sont très dispersés.
La moyenne ne suffit pas à distinguer ces deux situations. L’écart-type, lui, le fait : il est petit pour la classe A (environ 0,6) et grand pour la classe B (environ 4,9). Plus l’écart-type est grand, plus les valeurs s’éloignent de la moyenne.
Définition — Écart-type
L’écart-type d’une série statistique ou d’une variable aléatoire est la racine carrée positive de la variance. Il mesure la dispersion des valeurs autour de la moyenne.
\(\sigma = \sqrt{V}\)
Un écart-type petit signifie que les valeurs sont concentrées autour de la moyenne. Un écart-type grand signifie qu’elles sont dispersées.
B. Notation et unité
L’écart-type est noté \(\sigma\) (la lettre grecque « sigma »). Pour une variable aléatoire \(X\), on écrit \(\sigma(X)\) ou \(\sigma_X\).
L’unité de l’écart-type est la même que celle des données. Si tes données sont en centimètres, l’écart-type est en centimètres. Si tes notes sont sur 20, l’écart-type est en points.
C’est un avantage majeur sur la variance, qui s’exprime en « unités au carré » (cm², points²…) et qui est donc moins facile à interpréter directement.
C’est la raison principale pour laquelle l’écart-type est préféré à la variance en pratique : il se compare directement aux données. Si l’écart-type de tes notes vaut 2,5 points, tu sais immédiatement que tes notes s’écartent en moyenne d’environ 2,5 points de ta moyenne.
C. Extension CPGE — Écart-type corrigé (division par n−1)
En statistique inférentielle (programme de CPGE), on distingue deux écarts-types selon le contexte :
| Nom | Division par | Notation | Usage |
|---|---|---|---|
| Écart-type (population) | \(n\) | \(\sigma\) | Statistique descriptive, probabilités |
| Écart-type corrigé (échantillon) | \(n – 1\) | \(s\) | Estimation à partir d’un échantillon |
La division par \(n – 1\) corrige un biais systématique : lorsqu’on estime la variance d’une population à partir d’un échantillon, diviser par \(n\) sous-estime la vraie variance. Le facteur \(n – 1\) compense ce biais — on parle d’estimateur sans biais de la variance.
Attention au programme : au lycée (Seconde à Terminale), on divise toujours par \(n\). La division par \(n – 1\) n’apparaît qu’en CPGE et au-delà. Ne confonds pas les deux formules dans un exercice de bac !
Maintenant que tu sais ce qu’est l’écart-type, voyons les formules qui permettent de le calculer en statistiques et en probabilités.
II. Formules de l’écart-type
A. En statistiques (série de données)
Pour une série statistique de \(N\) valeurs \(x_1, x_2, \ldots, x_N\) de moyenne \(\bar{x}\) :
Formule de l’écart-type — Série statistique
\(\sigma = \sqrt{\displaystyle\frac{1}{N} \sum_{i=1}^{N} (x_i – \bar{x})^2}\)
Si les valeurs sont regroupées avec des effectifs \(n_i\) (et \(N = \sum n_i\)) :
\(\sigma = \sqrt{\displaystyle\frac{1}{N} \sum_{i} n_i \,(x_i – \bar{x})^2}\)
En d’autres termes : on calcule la moyenne des carrés des écarts à la moyenne, puis on prend la racine carrée.
B. En probabilités (variable aléatoire discrète)
Pour une variable aléatoire discrète \(X\) prenant les valeurs \(x_1, x_2, \ldots, x_k\) avec les probabilités \(P(X = x_i)\) :
Formule de l’écart-type — Variable aléatoire
\(\sigma(X) = \sqrt{V(X)}\)
avec :
\(\sigma(X) = \sqrt{\sum_{i=1}^{k} (x_i – E(X))^2 \cdot P(X = x_i)}\)
Ici, \(E(X)\) désigne l’espérance et \(V(X)\) la variance de la variable aléatoire.
C. Le raccourci de König-Huygens
Calculer chaque écart \((x_i – \bar{x})^2\) un par un est fastidieux. La formule de König-Huygens permet de calculer la variance — et donc l’écart-type — beaucoup plus vite :
Formule de König-Huygens
En statistiques : \(V = \overline{x^2} – \bar{x}^{\,2}\), soit : \(V = \displaystyle\frac{1}{N} \sum_{i=1}^{N} x_i^2 \;-\; \bar{x}^{\,2}\)
En probabilités : \(V(X) = E(X^2) – \left[E(X)\right]^2\)
Puis dans les deux cas : \(\sigma = \sqrt{V}\)
Retiens : « la moyenne des carrés moins le carré de la moyenne ».
Cette formule est la plus rapide en exercice : elle évite de recalculer les écarts à la moyenne. Tu trouveras sa démonstration détaillée sur la page consacrée à la variance.
D. Tableau récapitulatif des formules
| Contexte | Variance \(V\) | Écart-type \(\sigma\) |
|---|---|---|
| Série (données brutes) | \(\displaystyle\frac{1}{N}\sum(x_i – \bar{x})^2\) | \(\sqrt{V}\) |
| Série (avec effectifs) | \(\displaystyle\frac{1}{N}\sum n_i(x_i – \bar{x})^2\) | \(\sqrt{V}\) |
| Variable aléatoire discrète | \(\sum(x_i – E(X))^2 \cdot P(X\!=\!x_i)\) | \(\sqrt{V(X)}\) |
| König-Huygens (stats) | \(\overline{x^2} – \bar{x}^{\,2}\) | \(\sqrt{V}\) |
| König-Huygens (proba) | \(E(X^2) – [E(X)]^2\) | \(\sqrt{V(X)}\) |
Les formules sont posées. Appliquons-les maintenant sur des exemples concrets, étape par étape.
III. Méthode de calcul pas à pas
A. Calculer l’écart-type d’une série statistique
Voici la méthode en 4 étapes, applicable à tout exercice de statistiques :
- Calculer la moyenne \(\bar{x}\).
- Calculer les écarts au carré \((x_i – \bar{x})^2\) pour chaque valeur.
- Calculer la variance : c’est la moyenne de ces écarts au carré.
- Prendre la racine carrée : \(\sigma = \sqrt{V}\).
Exemple : Calculer l’écart-type de la série 5 ; 9 ; 8 ; 12 ; 6 ; 10 ; 6 ; 8.
Étape 1 — Moyenne :
\(\bar{x} = \displaystyle\frac{5 + 9 + 8 + 12 + 6 + 10 + 6 + 8}{8} = \displaystyle\frac{64}{8} = 8\)
Étape 2 — Écarts au carré :
| \(x_i\) | 5 | 9 | 8 | 12 | 6 | 10 | 6 | 8 |
|---|---|---|---|---|---|---|---|---|
| \(x_i – \bar{x}\) | −3 | 1 | 0 | 4 | −2 | 2 | −2 | 0 |
| \((x_i – \bar{x})^2\) | 9 | 1 | 0 | 16 | 4 | 4 | 4 | 0 |
Étape 3 — Variance :
\(V = \displaystyle\frac{9 + 1 + 0 + 16 + 4 + 4 + 4 + 0}{8} = \displaystyle\frac{38}{8} = 4{,}75\)
Étape 4 — Écart-type :
\(\sigma = \sqrt{4{,}75} \approx 2{,}18\)
L’écart-type vaut environ 2,18. Les valeurs s’écartent en moyenne d’environ 2,18 unités de la moyenne 8.
Vérification rapide avec König-Huygens :
\(\overline{x^2} = \displaystyle\frac{25 + 81 + 64 + 144 + 36 + 100 + 36 + 64}{8} = \displaystyle\frac{550}{8} = 68{,}75\)
\(V = 68{,}75 – 8^2 = 68{,}75 – 64 = 4{,}75\) ✓ On retrouve bien le même résultat.
B. Calculer l’écart-type d’une variable aléatoire discrète
En probabilités, la méthode la plus rapide utilise König-Huygens en 4 étapes :
- Calculer l’espérance \(E(X)\).
- Calculer \(E(X^2)\) (l’espérance des carrés).
- Appliquer König-Huygens : \(V(X) = E(X^2) – \left[E(X)\right]^2\).
- Prendre la racine carrée : \(\sigma(X) = \sqrt{V(X)}\).
Exemple : Un jeu attribue des points à chaque tour. La variable aléatoire \(X\) suit la loi :
| \(x_i\) | 0 | 3 | 6 |
|---|---|---|---|
| \(P(X = x_i)\) | 0,25 | 0,50 | 0,25 |
Étape 1 :
\(E(X) = 0 \times 0{,}25 + 3 \times 0{,}50 + 6 \times 0{,}25 = 0 + 1{,}5 + 1{,}5 = 3\)
Étape 2 :
\(E(X^2) = 0^2 \times 0{,}25 + 3^2 \times 0{,}50 + 6^2 \times 0{,}25 = 0 + 4{,}5 + 9 = 13{,}5\)
Étape 3 :
\(V(X) = 13{,}5 – 3^2 = 13{,}5 – 9 = 4{,}5\)
Étape 4 :
\(\sigma(X) = \sqrt{4{,}5} = \displaystyle\frac{3\sqrt{2}}{2} \approx 2{,}12\)
Les gains s’écartent en moyenne d’environ 2,12 points de l’espérance 3.
C. Calculer l’écart-type avec ta calculatrice
En contrôle et au bac, la calculatrice fait gagner un temps précieux. Voici la marche à suivre sur les trois modèles les plus répandus :
NumWorks :
- Ouvre l’application Régressions (ou Statistiques selon la version).
- Saisis tes valeurs dans la colonne \(X\) (et les effectifs dans \(N\) si besoin).
- L’onglet Stats affiche directement \(\sigma\).
TI-83 / TI-84 :
- Appuie sur STAT → Edit et saisis les données dans L1.
- Appuie sur STAT → CALC → 1-Var Stats → Entrée.
- Lis la ligne σx = (c’est l’écart-type avec division par \(n\)).
Casio Graph 35+ / 90+ :
- MENU → STAT → saisis les données dans List 1.
- Appuie sur CALC → 1VAR.
- Lis la valeur de \(\sigma x\).
Attention : les calculatrices affichent souvent deux écarts-types : \(\sigma x\) (division par \(n\)) et \(sx\) (division par \(n – 1\)). Au lycée, utilise toujours \(\sigma x\) (division par \(n\)).
Tu sais maintenant calculer un écart-type à la main et à la calculatrice. Découvrons les propriétés qui permettent de le manipuler sans tout recalculer.
IV. Propriétés et interprétation de l’écart-type
A. Propriétés opératoires
Propriétés de l’écart-type
Soit \(X\) une variable aléatoire, \(a \in \mathbb{R}\) et \(b \in \mathbb{R}\) :
- Positivité : \(\sigma(X) \geq 0\), et \(\sigma(X) = 0\) si et seulement si \(X\) est constante.
- Transformation affine : \(\sigma(aX + b) = |a| \cdot \sigma(X)\)
- Indépendance : si \(X\) et \(Y\) sont indépendantes, alors \(V(X + Y) = V(X) + V(Y)\).
La deuxième propriété signifie que translater les données (ajouter une constante \(b\)) ne change pas l’écart-type, tandis que dilater les données (multiplier par \(a\)) multiplie l’écart-type par \(|a|\).
Piège classique : l’écart-type d’une somme n’est PAS la somme des écarts-types !
❌ Écrire \(\sigma(X + Y) = \sigma(X) + \sigma(Y)\)
✅ Même avec \(X\) et \(Y\) indépendantes, c’est la variance qui s’additionne, pas l’écart-type :
\(\sigma(X + Y) = \sqrt{\sigma(X)^2 + \sigma(Y)^2}\)
![]()
B. Écart-type des lois classiques
Voici l’écart-type des principales lois de probabilité que tu rencontreras au lycée et en prépa :
| Loi | Paramètres | Espérance \(E(X)\) | Écart-type \(\sigma(X)\) |
|---|---|---|---|
| Bernoulli \(\mathcal{B}(p)\) | \(p \in \,]0\,;1[\) | \(p\) | \(\sqrt{p(1-p)}\) |
| Binomiale \(\mathcal{B}(n,p)\) | \(n \in \mathbb{N}^*,\; p \in \,]0\,;1[\) | \(np\) | \(\sqrt{np(1-p)}\) |
| Uniforme sur \([a\,;b]\) | \(a\) < \(b\) | \(\displaystyle\frac{a+b}{2}\) | \(\displaystyle\frac{b-a}{2\sqrt{3}}\) |
| Normale \(\mathcal{N}(\mu,\,\sigma^2)\) | \(\mu \in \mathbb{R},\;\sigma\) > \(0\) | \(\mu\) | \(\sigma\) |
| Exponentielle \(\mathcal{E}(\lambda)\) | \(\lambda\) > \(0\) | \(\displaystyle\frac{1}{\lambda}\) | \(\displaystyle\frac{1}{\lambda}\) |
| Poisson \(\mathcal{P}(\lambda)\) | \(\lambda\) > \(0\) | \(\lambda\) | \(\sqrt{\lambda}\) |
| Géométrique \(\mathcal{G}(p)\) | \(p \in \,]0\,;1[\) | \(\displaystyle\frac{1}{p}\) | \(\displaystyle\frac{\sqrt{1-p}}{p}\) |
Remarque : pour la loi normale, l’écart-type est directement un paramètre de la loi (le \(\sigma\) dans \(\mathcal{N}(\mu,\sigma^2)\)). Pour la loi exponentielle, l’espérance et l’écart-type sont égaux — un résultat à retenir.
C. Interprétation graphique — la règle 68-95-99,7
Pour une loi normale \(\mathcal{N}(\mu,\,\sigma^2)\), l’écart-type a une interprétation visuelle remarquable :
- 68 % des valeurs sont dans l’intervalle \([\mu – \sigma\,;\;\mu + \sigma]\)
- 95 % des valeurs sont dans \([\mu – 2\sigma\,;\;\mu + 2\sigma]\)
- 99,7 % des valeurs sont dans \([\mu – 3\sigma\,;\;\mu + 3\sigma]\)
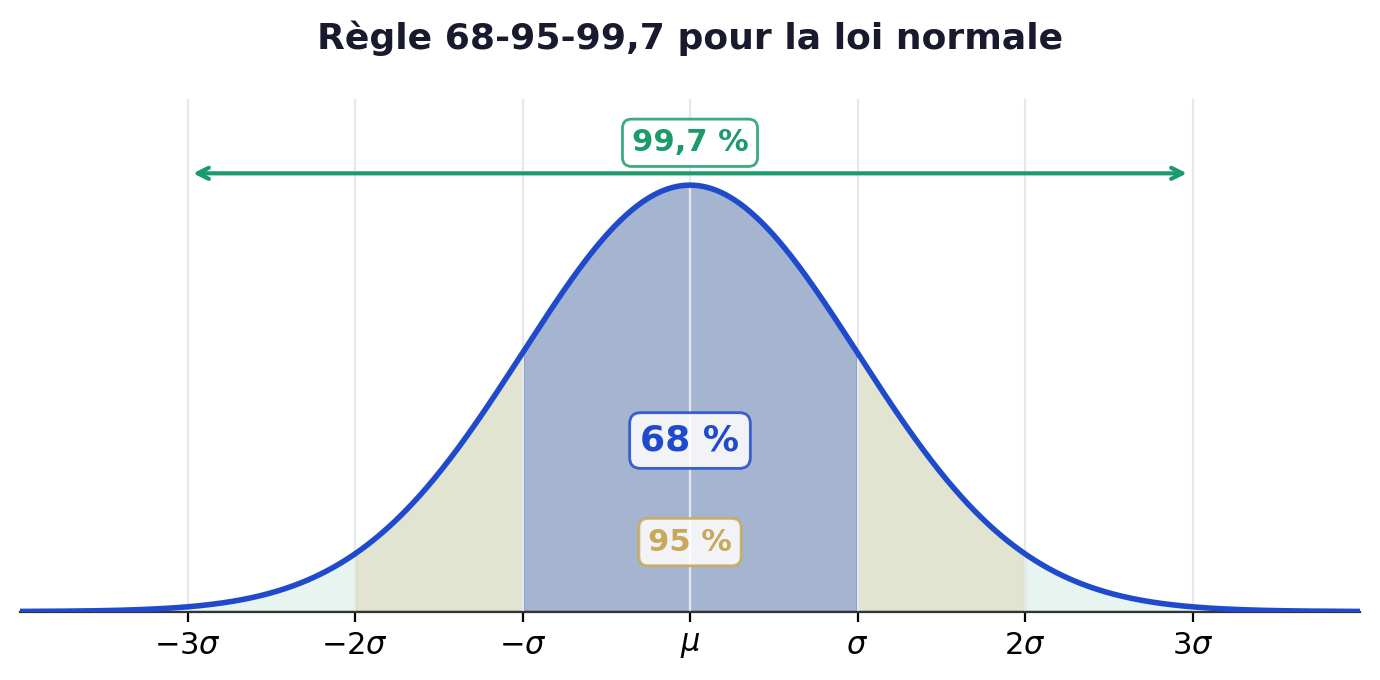
En pratique : si la taille des adultes français suit une loi normale de moyenne \(\mu = 170\) cm et d’écart-type \(\sigma = 6\) cm :
- Environ 68 % mesurent entre 164 cm et 176 cm.
- Environ 95 % mesurent entre 158 cm et 182 cm.
- Presque tout le monde (99,7 %) mesure entre 152 cm et 188 cm.
L’écart-type te donne directement une « fourchette » autour de la moyenne. Plus \(\sigma\) est petit, plus la courbe est resserrée et haute ; plus \(\sigma\) est grand, plus elle est étalée et aplatie.
Cette règle est spécifique à la loi normale. Pour d’autres distributions, l’inégalité de Bienaymé-Tchebychev ci-dessous donne des bornes universelles, valables quelle que soit la loi.
D. Extension CPGE — Inégalité de Bienaymé-Tchebychev
Cette inégalité fondamentale borne la probabilité qu’une variable aléatoire s’éloigne de son espérance, sans aucune hypothèse sur sa loi.
Théorème — Inégalité de Bienaymé-Tchebychev ⋆
Soit \(X\) une variable aléatoire d’espérance \(\mu = E(X)\) et de variance \(\sigma^2 = V(X)\) > \(0\). Pour tout réel \(\varepsilon\) > \(0\) :
\(P\!\left(|X – \mu| \geq \varepsilon\right) \leq \displaystyle\frac{\sigma^2}{\varepsilon^2}\)
Forme équivalente : pour tout \(k\) > \(0\) :
\(P\!\left(|X – \mu| \geq k\,\sigma\right) \leq \displaystyle\frac{1}{k^2}\)
Comparaison avec la loi normale :
Avec \(k = 2\) : Bienaymé-Tchebychev donne \(P(|X – \mu| \geq 2\sigma) \leq \displaystyle\frac{1}{4} = 25\,\%\).
Pour une loi normale, la valeur exacte est environ 5 %. L’inégalité de Bienaymé-Tchebychev est plus large (25 % vs 5 %), mais elle est universelle : elle vaut pour toute loi ayant une espérance et une variance finies.
Cette inégalité est utilisée en CPGE pour démontrer la loi faible des grands nombres et dans les problèmes de convergence en probabilité. Tu trouveras des exercices d’application dans nos exercices corrigés sur les variables aléatoires.
Place maintenant à la pratique avec 6 exercices classés par difficulté croissante.
V. Exercices corrigés
Voici 6 exercices progressifs pour vérifier ta maîtrise de l’écart-type. Essaie chaque exercice avant de consulter la correction.
Exercice 1 ★ — Série statistique
Les durées (en minutes) de 6 trajets domicile-lycée sont : 22 ; 18 ; 25 ; 20 ; 30 ; 23. Calculer la moyenne et l’écart-type de cette série.
▶ Voir la correction
Étape 1 — Moyenne :
\(\bar{x} = \displaystyle\frac{22 + 18 + 25 + 20 + 30 + 23}{6} = \displaystyle\frac{138}{6} = 23\)
Étape 2 — Écarts au carré :
\((22-23)^2 = 1 \quad;\quad (18-23)^2 = 25 \quad;\quad (25-23)^2 = 4\)
\((20-23)^2 = 9 \quad;\quad (30-23)^2 = 49 \quad;\quad (23-23)^2 = 0\)
Étape 3 — Variance :
\(V = \displaystyle\frac{1 + 25 + 4 + 9 + 49 + 0}{6} = \displaystyle\frac{88}{6} \approx 14{,}67\)
Étape 4 — Écart-type :
\(\sigma = \sqrt{14{,}67} \approx 3{,}83 \text{ min}\)
La durée moyenne du trajet est de 23 minutes, avec un écart-type d’environ 3,83 minutes. Les durées varient typiquement de ±4 minutes autour de la moyenne.
Exercice 2 ★ — Variable aléatoire discrète
Un dé truqué donne les résultats suivants :
| \(x_i\) | 1 | 3 | 5 |
|---|---|---|---|
| \(P(X = x_i)\) | 0,4 | 0,4 | 0,2 |
Calculer l’espérance et l’écart-type de \(X\).
▶ Voir la correction
Étape 1 — Espérance :
\(E(X) = 1 \times 0{,}4 + 3 \times 0{,}4 + 5 \times 0{,}2 = 0{,}4 + 1{,}2 + 1 = 2{,}6\)
Étape 2 — Espérance des carrés :
\(E(X^2) = 1^2 \times 0{,}4 + 3^2 \times 0{,}4 + 5^2 \times 0{,}2 = 0{,}4 + 3{,}6 + 5 = 9\)
Étape 3 — Variance (König-Huygens) :
\(V(X) = 9 – (2{,}6)^2 = 9 – 6{,}76 = 2{,}24\)
Étape 4 — Écart-type :
\(\sigma(X) = \sqrt{2{,}24} \approx 1{,}50\)
L’espérance est \(E(X) = 2{,}6\) et l’écart-type est \(\sigma(X) \approx 1{,}50\).
Exercice 3 ★★ — Loi binomiale (type bac)
Dans une usine, chaque pièce produite a une probabilité \(0{,}04\) d’être défectueuse (indépendamment des autres). On contrôle un lot de 150 pièces. Soit \(X\) le nombre de pièces défectueuses.
- Justifier que \(X\) suit une loi binomiale et donner ses paramètres.
- Calculer \(E(X)\) et \(\sigma(X)\).
- En déduire un intervalle contenant « la plupart » des valeurs de \(X\) (utiliser l’intervalle \([E(X) – 2\sigma\,;\;E(X) + 2\sigma]\)).
▶ Voir la correction
1. On répète 150 épreuves de Bernoulli indépendantes, chacune de probabilité de succès \(p = 0{,}04\). Donc \(X \sim \mathcal{B}(150\,;\;0{,}04)\).
2.
\(E(X) = np = 150 \times 0{,}04 = 6\)
\(\sigma(X) = \sqrt{np(1-p)} = \sqrt{150 \times 0{,}04 \times 0{,}96} = \sqrt{5{,}76} = 2{,}4\)
3.
\([E(X) – 2\sigma\;;\;E(X) + 2\sigma] = [6 – 4{,}8\;;\;6 + 4{,}8] = [1{,}2\;;\;10{,}8]\)
Comme \(X\) est à valeurs entières, on s’attend à ce qu’environ 95 % des lots contiennent entre 2 et 10 pièces défectueuses.
Exercice 4 ★★ — Transformation affine (raisonnement)
On sait que \(E(X) = 50\) et \(\sigma(X) = 8\). On pose \(Y = 3X – 10\).
- Calculer \(E(Y)\).
- Calculer \(\sigma(Y)\).
- Si on avait posé \(Z = -2X + 100\), que vaudrait \(\sigma(Z)\) ?
▶ Voir la correction
1. Par linéarité de l’espérance :
\(E(Y) = E(3X – 10) = 3 \times E(X) – 10 = 3 \times 50 – 10 = 140\)
2. En utilisant \(\sigma(aX + b) = |a| \cdot \sigma(X)\) :
\(\sigma(Y) = |3| \times \sigma(X) = 3 \times 8 = 24\)
3. Avec \(Z = -2X + 100\) :
\(\sigma(Z) = |-2| \times \sigma(X) = 2 \times 8 = 16\)
Attention : la valeur absolue est essentielle. Multiplier par \(-2\) donne le même écart-type que multiplier par \(+2\). L’ajout de la constante 100 ne change pas l’écart-type.
Exercice 5 ★★ — Interprétation (règle 68-95-99,7)
La masse d’un paquet de café suit une loi normale de moyenne \(\mu = 250\) g et d’écart-type \(\sigma = 5\) g.
- Dans quel intervalle se situent environ 95 % des masses ?
- Quelle est, approximativement, la probabilité qu’un paquet pèse moins de 240 g ?
- Sur un lot de 1 000 paquets, combien pèsent approximativement entre 245 g et 255 g ?
▶ Voir la correction
1. 95 % des valeurs sont dans \([\mu – 2\sigma\,;\;\mu + 2\sigma] = [250 – 10\,;\;250 + 10] = [240\,;\;260]\).
Environ 95 % des paquets pèsent entre 240 g et 260 g.
2. L’intervalle \([240\,;\;260]\) contient 95 % des masses. Les 5 % restants sont répartis symétriquement : 2,5 % en dessous de 240 g et 2,5 % au-dessus de 260 g.
Donc \(P(X\) < \(240) \approx 2{,}5\,\% = 0{,}025\).
3. L’intervalle \([245\,;\;255] = [\mu – \sigma\,;\;\mu + \sigma]\) contient environ 68 % des masses (règle du 68 %).
Sur 1 000 paquets : \(0{,}68 \times 1\,000 = 680\).
Environ 680 paquets pèsent entre 245 g et 255 g.
Exercice 6 ★★★ — Prépa — Inégalité de Bienaymé-Tchebychev
Soit \(X\) une variable aléatoire telle que \(E(X) = 80\) et \(\sigma(X) = 6\).
- À l’aide de l’inégalité de Bienaymé-Tchebychev, majorer \(P(|X – 80| \geq 18)\).
- En déduire un minorant de \(P(62\) < \(X\) < \(98)\).
- Si l’on sait de plus que \(X\) suit une loi normale, donner la valeur approchée de \(P(62\) < \(X\) < \(98)\) et comparer avec le résultat précédent.
▶ Voir la correction
1. On a \(\varepsilon = 18\) et \(\sigma(X) = 6\), donc \(k = \displaystyle\frac{18}{6} = 3\).
Bienaymé-Tchebychev donne : \(P(|X – 80| \geq 18) \leq \displaystyle\frac{1}{k^2} = \displaystyle\frac{1}{9} \approx 11{,}1\,\%\).
2. On en déduit :
\(P(62\) < \(X\) < \(98) = P(|X – 80|\) < \(18) \geq 1 – \displaystyle\frac{1}{9} = \displaystyle\frac{8}{9} \approx 88{,}9\,\%\)
3. Si \(X \sim \mathcal{N}(80,\,36)\), alors \(P(|X – 80|\) < \(18) = P(|X – 80|\) < \(3\sigma) \approx 99{,}7\,\%\) (règle des 3 écarts-types).
La valeur exacte (99,7 %) est bien supérieure au minorant universel (88,9 %). C’est normal : Bienaymé-Tchebychev donne une borne valable pour toute loi, donc nécessairement plus lâche qu’un calcul exact sous hypothèse de normalité.
L’essentiel de l’écart-type sur une fiche recto-verso
Définition, toutes les formules (stats + proba + König-Huygens), écart-type des lois classiques et la règle 68-95-99,7 — à glisser dans ton classeur.
Idéal pour réviser avant un contrôle ou le bac — tout tient en une page.
VI. Erreurs fréquentes et pièges classiques
Erreur n°1 — Confondre variance et écart-type
❌ « La dispersion vaut 4,75 » alors que 4,75 est la variance.
✅ La variance vaut \(V = 4{,}75\) et l’écart-type vaut \(\sigma = \sqrt{4{,}75} \approx 2{,}18\). N’oublie pas la racine carrée !
Erreur n°2 — Additionner les écarts-types
❌ Si \(\sigma(X) = 3\) et \(\sigma(Y) = 4\), écrire \(\sigma(X + Y) = 7\).
✅ Même avec \(X\) et \(Y\) indépendantes : \(\sigma(X + Y) = \sqrt{9 + 16} = \sqrt{25} = 5\). Ce sont les variances qui s’additionnent, pas les écarts-types.
Erreur n°3 — Diviser par n−1 au bac
❌ Utiliser \(\displaystyle\frac{1}{n-1}\sum(x_i – \bar{x})^2\) dans un exercice de lycée.
✅ Au lycée, on divise toujours par \(n\). La formule avec \(n – 1\) relève des CPGE.
Erreur n°4 — Oublier la valeur absolue
❌ Écrire \(\sigma(-2X + 5) = -2 \times \sigma(X)\).
✅ \(\sigma(-2X + 5) = |-2| \times \sigma(X) = 2\,\sigma(X)\). L’écart-type est toujours positif.
Erreur n°5 — Donner l’écart-type dans la mauvaise unité
❌ « L’écart-type des tailles vaut 36 cm² » (c’est la variance).
✅ L’écart-type est en cm, la variance est en cm². Si \(V = 36\) cm², alors \(\sigma = 6\) cm.
VII. Questions fréquentes
Comment expliquer l'écart-type simplement ?
L’écart-type mesure à quel point les valeurs d’une série ou d’une variable aléatoire s’éloignent de la moyenne. C’est la racine carrée de la variance. Un écart-type petit signifie que les valeurs sont groupées autour de la moyenne ; un écart-type grand signifie qu’elles sont dispersées. Son avantage sur la variance est qu’il s’exprime dans la même unité que les données.
Quelle est l'unité de l'écart-type ?
L’écart-type a la même unité que les données. Si tes données sont en mètres, l’écart-type est en mètres. Si tes données sont en euros, l’écart-type est en euros. C’est précisément ce qui le distingue de la variance, qui est exprimée en « unités au carré » (m², €²…).
Quelle est la différence entre l'écart-type et la variance ?
Les deux mesurent la dispersion. La variance \(V\) est la moyenne des carrés des écarts à la moyenne. L’écart-type \(\sigma\) est la racine carrée de la variance : \(\sigma = \sqrt{V}\). Concrètement, la variance est en « unités au carré » et l’écart-type est dans l’unité des données, ce qui le rend plus facile à interpréter. On préfère l’écart-type pour communiquer, et la variance pour les calculs (car elle a de meilleures propriétés algébriques).
Quel est l'écart-type de 5, 9, 8, 12, 6, 10, 6, 8 ?
La moyenne est \(\bar{x} = 8\). La variance vaut \(V = 4{,}75\) (somme des carrés des écarts = 38, divisée par 8). Donc l’écart-type est \(\sigma = \sqrt{4{,}75} \approx 2{,}18\). Le calcul complet étape par étape est détaillé dans la section Méthode de cet article.
L'écart-type peut-il être négatif ?
Non, jamais. L’écart-type est défini comme la racine carrée positive de la variance. La variance est elle-même une somme de carrés, donc toujours positive ou nulle. Par conséquent, \(\sigma \geq 0\). Le seul cas où \(\sigma = 0\) est lorsque toutes les valeurs sont identiques (dispersion nulle).
Pourquoi diviser par n moins 1 pour l'écart-type d'un échantillon ?
Quand on calcule la variance d’un échantillon pour estimer la variance de la population, la moyenne \(\bar{x}\) est elle-même calculée à partir de l’échantillon, ce qui « gaspille » un degré de liberté. Diviser par \(n – 1\) au lieu de \(n\) compense ce biais et donne un estimateur sans biais de la variance. Au lycée, on utilise toujours \(n\) ; la formule avec \(n – 1\) relève du programme de CPGE.
Quelle est la différence entre l'écart-type et l'erreur type de la moyenne ?
L’écart-type \(\sigma\) mesure la dispersion des valeurs individuelles autour de la moyenne. L’erreur type de la moyenne (ou erreur standard) vaut \(\displaystyle\frac{\sigma}{\sqrt{n}}\) : elle mesure la précision de l’estimation de la moyenne à partir d’un échantillon de taille \(n\). Plus l’échantillon est grand, plus l’erreur type diminue, alors que l’écart-type reste le même.
VIII. Pour aller plus loin
Tu maîtrises maintenant l’écart-type : définition, formules, méthode de calcul et propriétés. Pour approfondir, voici les ressources complémentaires du cours :
- Variance : formule, calcul et propriétés — la notion jumelle de l’écart-type, avec la démonstration de König-Huygens
- Espérance : formule et calcul — indispensable pour calculer la variance et l’écart-type
- Loi binomiale : cours et formules — la loi la plus fréquente au bac, avec \(\sigma = \sqrt{np(1-p)}\)
- Loi normale : cours et propriétés — pour approfondir la règle 68-95-99,7
- Table de la loi normale centrée réduite — pour lire les probabilités exactes
- Exercices corrigés sur les variables aléatoires — pour t’entraîner davantage
![]()




