Rédigé et vérifié par un professeur diplômé de l’École Polytechnique, avec le niveau d’exigence attendu en classe préparatoire. Découvrir le professeur
Une matrice est un tableau rectangulaire de nombres, organisé en lignes et en colonnes. Au programme de Terminale Spécialité Mathématiques puis approfondi tout au long des CPGE scientifiques (MPSI, PCSI, MP, PC, PSI), le calcul matriciel est l’outil fondamental de l’algèbre linéaire. Tu trouveras ici : définitions formelles, types de matrices, opérations (produit, inverse, déterminant), méthodes de calcul, 6 exercices corrigés progressifs et les pièges classiques à éviter.
Le tableau ci-dessous te situe dans la progression : chaque notion est rattachée au niveau où elle apparaît pour la première fois. Utilise-le pour identifier les sections qui te concernent.
| Notion | 🟢 Terminale Spé | 🔵 CPGE 1re année | 🔴 CPGE 2e année |
|---|---|---|---|
| Définition, notation, types de base | ✅ | — | — |
| Addition, multiplication par un scalaire | ✅ | — | — |
| Produit matriciel | ✅ (2×2, 3×3) | ✅ (taille quelconque) | — |
| Déterminant | — | ✅ (\(n \times n\)) | — |
| Inverse d’une matrice | ✅ (formule 2×2) | ✅ (Gauss, comatrice) | — |
| Rang, noyau, image | — | ✅ | — |
| Diagonalisation, valeurs propres | — | ✅ | ✅ (réduction) |
| Applications linéaires, changement de base | — | ✅ | ✅ |
| Matrices symétriques, orthogonales, théorème spectral | — | — | ✅ |
| Espaces vectoriels, sous-espaces | — | ✅ | ✅ |
Fiche de révision — Matrices : l’essentiel en 2 pages
Définitions, formules clés, types de matrices, critères d’inversibilité et pièges à éviter. Le résumé parfait avant un DS ou un concours.
📄 Télécharger la fiche PDF gratuiteUtilisée par plus de 5 000 élèves de prépa pour réviser efficacement.
I. Définitions et notions fondamentales
A. Définition formelle d’une matrice
Définition — Matrice
Soit \(\mathbb{K}\) un corps (typiquement \(\mathbb{R}\) ou \(\mathbb{C}\)). Une matrice à \(m\) lignes et \(n\) colonnes à coefficients dans \(\mathbb{K}\) est un tableau rectangulaire :
\(A = \begin{pmatrix} a_{1,1} & a_{1,2} & \cdots & a_{1,n} \\ a_{2,1} & a_{2,2} & \cdots & a_{2,n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m,1} & a_{m,2} & \cdots & a_{m,n} \end{pmatrix}\)
On note \(A = (a_{i,j})\) pour \(1 \leq i \leq m\) et \(1 \leq j \leq n\). Le scalaire \(a_{i,j} \in \mathbb{K}\) est le coefficient situé à la ligne \(i\) et à la colonne \(j\).
L’ensemble des matrices à \(m\) lignes et \(n\) colonnes à coefficients dans \(\mathbb{K}\) se note \(\mathcal{M}_{m,n}(\mathbb{K})\). Lorsque \(m = n\), on parle de matrice carrée d’ordre \(n\) et on note simplement \(\mathcal{M}_n(\mathbb{K})\).
Exemple. La matrice \(A = \begin{pmatrix} 3 & -1 & 0 \\ 2 & 5 & 7 \end{pmatrix}\) appartient à \(\mathcal{M}_{2,3}(\mathbb{R})\) : elle a 2 lignes et 3 colonnes. Le coefficient \(a_{1,2} = -1\) est situé en ligne 1, colonne 2.
B. Vocabulaire et conventions de notation
Quelques termes à maîtriser dès le début :
- Taille (ou format) : le couple \((m, n)\). On dit que \(A\) est une matrice \(m \times n\).
- Matrice colonne : matrice de taille \(m \times 1\), identifiable à un vecteur de \(\mathbb{K}^m\).
- Matrice ligne : matrice de taille \(1 \times n\).
- Coefficients diagonaux : les \(a_{i,i}\) pour \(1 \leq i \leq \min(m,n)\).
Convention française. En CPGE scientifique, la notation standard est \(\mathcal{M}_{m,n}(\mathbb{K})\) avec un \(\mathcal{M}\) caligraphié. Les notations \(M_{m \times n}\) ou \(\mathrm{Mat}_{m,n}\) se rencontrent dans la littérature mais ne sont pas celles des programmes français.
C. Types fondamentaux de matrices
Les matrices se classent selon leur structure. Ce tableau synthétise les types que tu rencontreras tout au long de tes études, de la Terminale à la prépa. Chaque type fait l’objet d’une page dédiée dans ce cours.
| Type | Notation / Condition | Exemple (2×2 ou 3×3) | Niveau |
|---|---|---|---|
| Identité | \(I_n\) : \(a_{i,j} = \delta_{i,j}\) | \(\begin{pmatrix} 1 & 0 \\ 0 & 1 \end{pmatrix}\) | 🟢 Terminale |
| Nulle | \(0_{m,n}\) : tous les coefficients nuls | \(\begin{pmatrix} 0 & 0 \\ 0 & 0 \end{pmatrix}\) | 🟢 Terminale |
| Diagonale | \(a_{i,j} = 0\) si \(i \neq j\) | \(\begin{pmatrix} 3 & 0 \\ 0 & -2 \end{pmatrix}\) | 🟢 Terminale |
| Triangulaire supérieure | \(a_{i,j} = 0\) si \(i\) > \(j\) | \(\begin{pmatrix} 1 & 4 & 2 \\ 0 & 3 & 5 \\ 0 & 0 & 7 \end{pmatrix}\) | 🔵 CPGE 1A |
| Symétrique | \(A^T = A\) | \(\begin{pmatrix} 1 & 3 \\ 3 & 5 \end{pmatrix}\) | 🔵 CPGE 1A |
| Antisymétrique | \(A^T = -A\) | \(\begin{pmatrix} 0 & 2 \\ -2 & 0 \end{pmatrix}\) | 🔵 CPGE 1A |
| Orthogonale | \(A^T A = I_n\) | \(\begin{pmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{pmatrix}\) | 🔴 CPGE 2A |
| Nilpotente | \(\exists\, k \in \mathbb{N}^*,\; A^k = 0\) | \(\begin{pmatrix} 0 & 1 \\ 0 & 0 \end{pmatrix}\) | 🔴 CPGE 2A |
La matrice diagonale mérite une attention particulière : c’est une matrice carrée dont tous les coefficients hors de la diagonale principale sont nuls. L’intérêt fondamental des matrices diagonales est que toutes les opérations y deviennent triviales — le produit, l’inverse, la puissance \(n\)-ième se calculent coefficient par coefficient sur la diagonale. C’est précisément pourquoi la diagonalisation (ramener une matrice à une forme diagonale) est un objectif central de l’algèbre linéaire.
Les matrices dans la vie réelle. Les matrices ne sont pas un objet abstrait confiné aux mathématiques pures. Elles interviennent en cryptographie (chiffrement de Hill), en infographie et jeux vidéo (rotations, projections, transformations 3D), en machine learning (poids des réseaux de neurones, matrices de covariance), en physique quantique (opérateurs) et en économie (modèle de Leontief). Chaque fois qu’un système met en jeu des relations linéaires entre plusieurs grandeurs, les matrices sont l’outil naturel pour le modéliser.
II. Opérations sur les matrices
L’ensemble \(\mathcal{M}_{m,n}(\mathbb{K})\) est naturellement muni d’une structure d’espace vectoriel. Le produit matriciel, lui, n’est défini que sous certaines conditions de compatibilité des tailles.
A. Addition et multiplication par un scalaire
Définition — Somme et produit par un scalaire
Soient \(A = (a_{i,j})\) et \(B = (b_{i,j})\) deux matrices de \(\mathcal{M}_{m,n}(\mathbb{K})\), et \(\lambda \in \mathbb{K}\).
- Somme : \(A + B = (a_{i,j} + b_{i,j})\) (addition coefficient par coefficient).
- Produit par un scalaire : \(\lambda A = (\lambda \, a_{i,j})\).
Ces deux opérations font de \(\mathcal{M}_{m,n}(\mathbb{K})\) un espace vectoriel de dimension \(mn\) sur \(\mathbb{K}\). L’élément neutre pour l’addition est la matrice nulle \(0_{m,n}\).
Exemple. Soient \(A = \begin{pmatrix} 1 & 3 \\ -2 & 0 \end{pmatrix}\) et \(B = \begin{pmatrix} 4 & -1 \\ 5 & 2 \end{pmatrix}\). Alors :
\(A + B = \begin{pmatrix} 5 & 2 \\ 3 & 2 \end{pmatrix}, \qquad 3A = \begin{pmatrix} 3 & 9 \\ -6 & 0 \end{pmatrix}\)
B. Produit de deux matrices
Le produit matriciel est l’opération la plus riche — et la plus piégeuse — du calcul matriciel. Sa définition repose sur un mécanisme « ligne par colonne ». Pour un traitement complet, consulte la page dédiée à la multiplication de matrices.
Définition — Produit matriciel
Soient \(A \in \mathcal{M}_{m,n}(\mathbb{K})\) et \(B \in \mathcal{M}_{n,p}(\mathbb{K})\). Le produit \(AB\) est la matrice \(C \in \mathcal{M}_{m,p}(\mathbb{K})\) définie par :
\(c_{i,j} = \sum_{k=1}^{n} a_{i,k}\, b_{k,j}\)
Le nombre de colonnes de \(A\) doit être égal au nombre de lignes de \(B\).
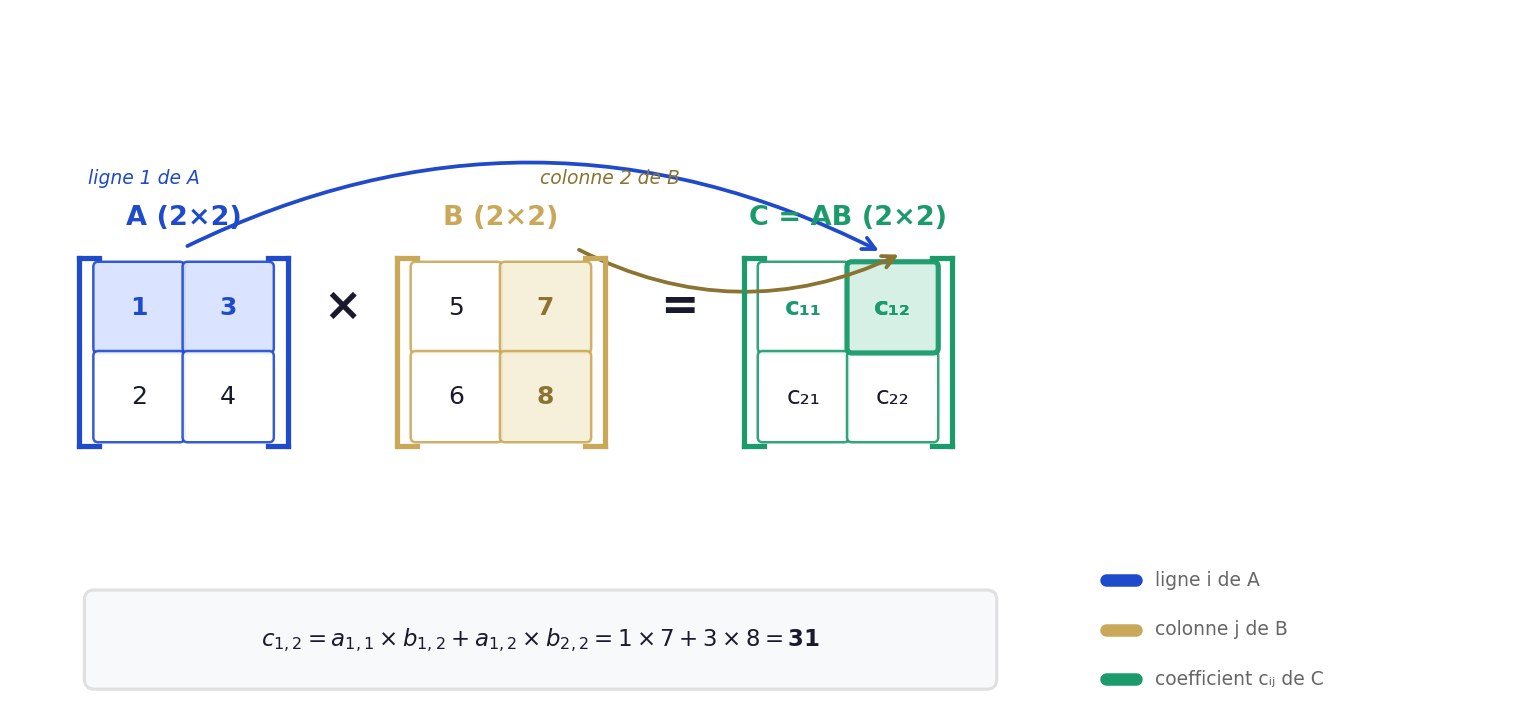
Exemple. Soient \(A = \begin{pmatrix} 1 & 2 \\ 3 & 4 \end{pmatrix}\) et \(B = \begin{pmatrix} 5 & 6 \\ 7 & 8 \end{pmatrix}\). Alors :
\(AB = \begin{pmatrix} 1 \times 5 + 2 \times 7 & 1 \times 6 + 2 \times 8 \\ 3 \times 5 + 4 \times 7 & 3 \times 6 + 4 \times 8 \end{pmatrix} = \begin{pmatrix} 19 & 22 \\ 43 & 50 \end{pmatrix}\)
Propriétés fondamentales du produit. Pour toutes matrices de tailles compatibles et tout scalaire \(\lambda \in \mathbb{K}\) :
- Associativité : \((AB)C = A(BC)\).
- Distributivité : \(A(B + C) = AB + AC\) et \((A + B)C = AC + BC\).
- Élément neutre : \(I_n \, A = A \, I_n = A\) pour toute \(A \in \mathcal{M}_n(\mathbb{K})\).
- Compatibilité scalaire : \(\lambda(AB) = (\lambda A)B = A(\lambda B)\).
⚠ Le produit matriciel n’est PAS commutatif. En général, \(AB \neq BA\). C’est la première source d’erreur en calcul matriciel. Contre-exemple immédiat : avec \(A = \begin{pmatrix} 1 & 0 \\ 0 & 0 \end{pmatrix}\) et \(B = \begin{pmatrix} 0 & 1 \\ 0 & 0 \end{pmatrix}\), on obtient \(AB = B\) mais \(BA = 0\).
C. Transposée et trace
Deux opérations complémentaires interviennent constamment dans l’étude des matrices.
Transposée. La transposée de \(A = (a_{i,j}) \in \mathcal{M}_{m,n}(\mathbb{K})\) est la matrice \(A^T \in \mathcal{M}_{n,m}(\mathbb{K})\) définie par \((A^T)_{i,j} = a_{j,i}\). Les lignes deviennent les colonnes et réciproquement.
Propriétés essentielles : \((A + B)^T = A^T + B^T\), \((\lambda A)^T = \lambda A^T\), \((A^T)^T = A\), et surtout :
\((AB)^T = B^T A^T\)L’inversion de l’ordre dans la transposée du produit est un résultat classique à retenir.
Trace. 🔵 Pour une matrice carrée \(A \in \mathcal{M}_n(\mathbb{K})\), la trace est la somme des coefficients diagonaux :
\(\mathrm{tr}(A) = \sum_{i=1}^{n} a_{i,i}\)La trace est linéaire (\(\mathrm{tr}(A + \lambda B) = \mathrm{tr}(A) + \lambda\, \mathrm{tr}(B)\)) et vérifie \(\mathrm{tr}(AB) = \mathrm{tr}(BA)\) — une des rares situations où l’ordre dans un produit n’a pas d’impact. En CPGE, la trace est reliée aux valeurs propres : \(\mathrm{tr}(A) = \sum \lambda_i\).
III. Propriétés structurelles et invariants
Trois invariants permettent de caractériser le comportement d’une matrice carrée : le déterminant, l’inversibilité et le rang. Ils sont profondément liés entre eux.
A. Déterminant d’une matrice
Le déterminant associe un scalaire à toute matrice carrée. Il encode des informations cruciales sur la matrice (inversibilité, volume, orientation).
Définition — Déterminant en dimension 2 🟢
Pour \(A = \begin{pmatrix} a & b \\ c & d \end{pmatrix} \in \mathcal{M}_2(\mathbb{K})\) :
\(\det(A) = ad – bc\)
En dimension \(n \geq 3\), le déterminant se calcule par développement selon une ligne ou une colonne (cofacteurs) ou par réduction de Gauss. La règle de Sarrus offre un raccourci en dimension 3 et le développement par cofacteurs s’applique en dimension quelconque.
Propriétés fondamentales. Pour \(A, B \in \mathcal{M}_n(\mathbb{K})\) et \(\lambda \in \mathbb{K}\) :
- Multiplicativité : \(\det(AB) = \det(A) \cdot \det(B)\).
- Transposée : \(\det(A^T) = \det(A)\).
- Homogénéité : \(\det(\lambda A) = \lambda^n \det(A)\).
- Critère d’inversibilité : \(A\) est inversible \(\iff \det(A) \neq 0\).
Erreur fatale. Le déterminant n’est pas additif : \(\det(A + B) \neq \det(A) + \det(B)\) en général. Contre-exemple : \(\det(I_2 + I_2) = \det(2I_2) = 4 \neq 2 = \det(I_2) + \det(I_2)\).
B. Inversibilité et calcul de l’inverse
L’inversibilité est la question la plus naturelle qu’on puisse poser sur une matrice carrée : existe-t-il une matrice « réciproque » qui annule l’effet du produit ?
Définition — Matrice inversible
Une matrice \(A \in \mathcal{M}_n(\mathbb{K})\) est dite inversible s’il existe \(B \in \mathcal{M}_n(\mathbb{K})\) telle que \(AB = BA = I_n\). La matrice \(B\), unique, est notée \(A^{-1}\).
Critères d’inversibilité (équivalences fondamentales pour \(A \in \mathcal{M}_n(\mathbb{K})\)) :
- \(\det(A) \neq 0\)
- \(\mathrm{rg}(A) = n\) (rang maximal)
- \(\ker(A) = \{0\}\) (noyau trivial)
- Les colonnes de \(A\) forment une famille libre de \(\mathbb{K}^n\)
- \(0\) n’est pas valeur propre de \(A\)
En pratique, le calcul de l’inverse se fait par plusieurs méthodes selon la taille et le contexte :
🟢 En dimension 2 — formule directe :
\(A^{-1} = \displaystyle\frac{1}{ad – bc} \begin{pmatrix} d & -b \\ -c & a \end{pmatrix}\)🔵 En dimension \(n\) — deux méthodes principales :
- Méthode de Gauss-Jordan (pivot de Gauss) : on échelonne \((A \mid I_n)\) pour obtenir \((I_n \mid A^{-1})\). C’est la méthode la plus efficace en pratique. Voir l’inverse d’une matrice 3×3.
- Comatrice (matrice adjointe) : \(A^{-1} = \displaystyle\frac{1}{\det(A)} \, \mathrm{com}(A)^T\). Plus théorique, utile pour les formules générales.
L’inverse d’une matrice est traitée en détail dans la page dédiée, avec des exemples pour chaque méthode.
C. Rang d’une matrice
Le rang mesure la « taille effective » de l’information portée par une matrice. 🔵
Définition — Rang
Le rang de \(A \in \mathcal{M}_{m,n}(\mathbb{K})\), noté \(\mathrm{rg}(A)\), est la dimension du sous-espace vectoriel engendré par les colonnes de \(A\) (ou, de manière équivalente, par ses lignes).
Calcul en pratique. On réduit \(A\) par la méthode de Gauss (opérations élémentaires sur les lignes) : le rang est le nombre de pivots non nuls dans la forme échelonnée. C’est la méthode la plus rapide en DS et en concours.
Le théorème du rang relie le noyau et l’image d’une matrice \(A \in \mathcal{M}_{m,n}(\mathbb{K})\) :
\(\mathrm{rg}(A) + \dim(\ker A) = n\)Ce théorème est un outil central pour les problèmes de CPGE : il permet de déduire la dimension du noyau à partir du rang, et réciproquement.
IV. Diagonalisation et algèbre linéaire
Les notions de ce chapitre constituent le cœur du programme de CPGE. Elles relient le calcul matriciel à la théorie des espaces vectoriels et des applications linéaires.
A. Valeurs propres et vecteurs propres
Définition — Valeur propre, vecteur propre 🔵
Soit \(A \in \mathcal{M}_n(\mathbb{K})\). Un scalaire \(\lambda \in \mathbb{K}\) est une valeur propre de \(A\) s’il existe un vecteur non nul \(X \in \mathbb{K}^n\) tel que :
\(AX = \lambda X\)
Le vecteur \(X\) est alors un vecteur propre associé à \(\lambda\). L’ensemble \(E_\lambda = \ker(A – \lambda I_n)\) est le sous-espace propre associé.
Les valeurs propres sont les racines du polynôme caractéristique \(\chi_A(\lambda) = \det(A – \lambda I_n)\). Le déterminant intervient donc directement dans le calcul du spectre.
Deux résultats fondamentaux relient le spectre à la trace et au déterminant. Si \(\lambda_1, \ldots, \lambda_n\) sont les valeurs propres de \(A\) (comptées avec multiplicité) :
- \(\mathrm{tr}(A) = \lambda_1 + \cdots + \lambda_n\)
- \(\det(A) = \lambda_1 \times \cdots \times \lambda_n\)
Consulte la page valeurs propres et vecteurs propres pour les démonstrations et les méthodes de calcul détaillées.
B. Diagonalisation d’une matrice
La diagonalisation consiste à trouver une matrice inversible \(P\) et une matrice diagonale \(D\) telles que :
\(A = PDP^{-1}\)L’intérêt est immédiat : le calcul de \(A^n\) se ramène au calcul de \(D^n\), qui est trivial (on élève chaque coefficient diagonal à la puissance \(n\)). Voir la page matrice puissance pour les applications.
Méthode de diagonalisation en 5 étapes.
- Calculer \(\chi_A(\lambda) = \det(A – \lambda I_n)\).
- Trouver les valeurs propres (racines de \(\chi_A\)).
- Pour chaque \(\lambda_i\), déterminer \(E_{\lambda_i} = \ker(A – \lambda_i I_n)\).
- Vérifier que \(\sum \dim E_{\lambda_i} = n\) (condition nécessaire et suffisante).
- Former \(P\) avec les vecteurs propres en colonnes, \(D = \mathrm{diag}(\lambda_1, \ldots, \lambda_n)\).
Théorème spectral 🔴 : toute matrice symétrique réelle est diagonalisable dans une base orthonormée. La matrice de passage \(P\) est alors orthogonale.
C. Matrices et applications linéaires
Une matrice n’est pas qu’un tableau de nombres : c’est la représentation d’une application linéaire dans une base. 🔵
Soit \(f : E \to F\) une application linéaire entre deux \(\mathbb{K}\)-espaces vectoriels de dimension finie, \(\mathcal{B}\) une base de \(E\) et \(\mathcal{C}\) une base de \(F\). La matrice de \(f\) dans les bases \((\mathcal{B}, \mathcal{C})\) est la matrice dont la \(j\)-ème colonne contient les coordonnées de \(f(e_j)\) dans \(\mathcal{C}\).
Lorsqu’on change de base, la matrice de \(f\) se transforme par la formule de changement de base :
\(M_{\mathcal{B}^\prime, \mathcal{C}^\prime}(f) = Q^{-1} \, M_{\mathcal{B}, \mathcal{C}}(f) \, P\)où \(P\) et \(Q\) sont les matrices de changement de base. La diagonalisation est un cas particulier : on cherche une base dans laquelle la matrice est diagonale.
D. Espaces vectoriels et sous-espaces vectoriels
Les espaces vectoriels fournissent le cadre abstrait dans lequel vivent les matrices. Les notions de base, de dimension, de famille libre et génératrice sont les outils qui permettent de comprendre pourquoi les matrices fonctionnent comme elles fonctionnent. 🔵
Un sous-espace vectoriel est un sous-ensemble stable par les opérations de l’espace. Le noyau et l’image d’une matrice en sont les exemples les plus importants, et le théorème du rang lie leurs dimensions.
Pour vérifier qu’un sous-ensemble \(F\) est un sous-espace vectoriel de \(E\), il suffit de montrer trois points : \(F \neq \emptyset\) (ou \(0 \in F\)), stabilité par addition et stabilité par multiplication scalaire. Cette méthode systématique est détaillée dans la page sous-espaces vectoriels.
V. Exercices corrigés progressifs
Voici 6 exercices classés par difficulté croissante, de la Terminale Spécialité au niveau concours. Chaque correction est détaillée pas à pas. Pour un entraînement intensif, consulte les exercices corrigés sur les matrices (20+ exercices) et les exercices sur les espaces vectoriels.
Exercice 1 ★ — Produit de matrices 2×2 🟢 Terminale
Soient \(A = \begin{pmatrix} 2 & -1 \\ 3 & 4 \end{pmatrix}\) et \(B = \begin{pmatrix} 1 & 5 \\ -2 & 0 \end{pmatrix}\). Calculer \(AB\) et \(BA\). Que constate-t-on ?
Voir la correction
Calcul de \(AB\).
\(AB = \begin{pmatrix} 2 \times 1 + (-1) \times (-2) & 2 \times 5 + (-1) \times 0 \\ 3 \times 1 + 4 \times (-2) & 3 \times 5 + 4 \times 0 \end{pmatrix} = \begin{pmatrix} 4 & 10 \\ -5 & 15 \end{pmatrix}\)Calcul de \(BA\).
\(BA = \begin{pmatrix} 1 \times 2 + 5 \times 3 & 1 \times (-1) + 5 \times 4 \\ (-2) \times 2 + 0 \times 3 & (-2) \times (-1) + 0 \times 4 \end{pmatrix} = \begin{pmatrix} 17 & 19 \\ -4 & 2 \end{pmatrix}\)Conclusion : \(AB \neq BA\). Le produit matriciel n’est pas commutatif.
Exercice 2 ★ — Inversibilité et inverse d’une matrice 2×2 🟢 Terminale
Soit \(M = \begin{pmatrix} 3 & -1 \\ 2 & 5 \end{pmatrix}\). La matrice \(M\) est-elle inversible ? Si oui, calculer \(M^{-1}\).
Voir la correction
Étape 1 — Vérifier l’inversibilité.
Pour une matrice \(\begin{pmatrix} a & b \\ c & d \end{pmatrix}\), on calcule \(ad – bc\). Si ce nombre est non nul, la matrice est inversible.
\(ad – bc = 3 \times 5 – (-1) \times 2 = 15 + 2 = 17 \neq 0\)La matrice \(M\) est donc inversible.
Étape 2 — Calculer l’inverse.
La formule de l’inverse d’une matrice 2×2 donne :
\(M^{-1} = \displaystyle\frac{1}{17} \begin{pmatrix} 5 & 1 \\ -2 & 3 \end{pmatrix}\)On permute les éléments diagonaux (3 et 5), on change le signe des éléments anti-diagonaux (\(-1\) devient \(1\), \(2\) devient \(-2\)), et on divise par \(17\).
Vérification :
\(M \times M^{-1} = \begin{pmatrix} 3 & -1 \\ 2 & 5 \end{pmatrix} \times \displaystyle\frac{1}{17}\begin{pmatrix} 5 & 1 \\ -2 & 3 \end{pmatrix} = \displaystyle\frac{1}{17}\begin{pmatrix} 17 & 0 \\ 0 & 17 \end{pmatrix} = I_2 \quad \text{✓}\)Exercice 3 ★★ — Calcul de l’inverse en dimension 2 🔵 CPGE 1A
Soit \(A = \begin{pmatrix} 2 & 1 \\ 5 & 3 \end{pmatrix}\). Calculer \(A^{-1}\) et vérifier que \(AA^{-1} = I_2\).
Voir la correction
Étape 1 — Déterminant.
\(\det(A) = 2 \times 3 – 1 \times 5 = 6 – 5 = 1\)Comme \(\det(A) = 1 \neq 0\), \(A\) est inversible.
Étape 2 — Formule de l’inverse en dimension 2.
\(A^{-1} = \displaystyle\frac{1}{\det(A)} \begin{pmatrix} d & -b \\ -c & a \end{pmatrix} = \displaystyle\frac{1}{1} \begin{pmatrix} 3 & -1 \\ -5 & 2 \end{pmatrix} = \begin{pmatrix} 3 & -1 \\ -5 & 2 \end{pmatrix}\)Étape 3 — Vérification.
\(AA^{-1} = \begin{pmatrix} 2 & 1 \\ 5 & 3 \end{pmatrix} \begin{pmatrix} 3 & -1 \\ -5 & 2 \end{pmatrix} = \begin{pmatrix} 6-5 & -2+2 \\ 15-15 & -5+6 \end{pmatrix} = \begin{pmatrix} 1 & 0 \\ 0 & 1 \end{pmatrix} = I_2 \quad \text{✓}\)20 exercices corrigés sur les matrices — PDF offert
Produit, déterminant, inverse, diagonalisation : tous les types d’exercices tombés en DS et aux concours, avec corrections détaillées.
📄 Recevoir les exercices PDFLe PDF idéal pour s’entraîner la veille d’un DS sur les matrices.
Exercice 4 ★★ — Déterminant 3×3 par Sarrus et cofacteurs 🔵 CPGE 1A
Soit \(M = \begin{pmatrix} 1 & 2 & 3 \\ 0 & 4 & 5 \\ 1 & 0 & 2 \end{pmatrix}\). Calculer \(\det(M)\) de deux manières : par la règle de Sarrus, puis par développement selon la première colonne.
Voir la correction
Méthode 1 — Règle de Sarrus.
On recopie les deux premières colonnes à droite, puis on calcule :
\(\det(M) = (1 \times 4 \times 2) + (2 \times 5 \times 1) + (3 \times 0 \times 0) – (3 \times 4 \times 1) – (2 \times 0 \times 2) – (1 \times 5 \times 0)\) \(= 8 + 10 + 0 – 12 – 0 – 0 = 6\)Méthode 2 — Développement selon la première colonne \(C_1\).
On choisit \(C_1\) car elle contient un zéro (coefficient \(a_{2,1} = 0\)), ce qui simplifie le calcul :
\(\det(M) = 1 \times \begin{vmatrix} 4 & 5 \\ 0 & 2 \end{vmatrix} – 0 \times \begin{vmatrix} 2 & 3 \\ 0 & 2 \end{vmatrix} + 1 \times \begin{vmatrix} 2 & 3 \\ 4 & 5 \end{vmatrix}\) \(= 1 \times (8 – 0) – 0 + 1 \times (10 – 12) = 8 + (-2) = 6\)Les deux méthodes donnent bien \(\det(M) = 6\).
Exercice 5 ★★★ — Diagonalisation et calcul de \(A^n\) 🔵 CPGE
Soit \(A = \begin{pmatrix} 3 & 1 \\ 0 & 2 \end{pmatrix}\). Montrer que \(A\) est diagonalisable, puis déterminer \(A^n\) pour tout \(n \in \mathbb{N}\).
Voir la correction
Étape 1 — Polynôme caractéristique.
\(\chi_A(\lambda) = \det(A – \lambda I_2) = \det \begin{pmatrix} 3 – \lambda & 1 \\ 0 & 2 – \lambda \end{pmatrix} = (3 – \lambda)(2 – \lambda)\)Étape 2 — Valeurs propres.
\(\chi_A(\lambda) = 0 \iff \lambda = 3 \text{ ou } \lambda = 2\)Deux valeurs propres distinctes en dimension 2 : \(A\) est diagonalisable.
Étape 3 — Espaces propres.
Pour \(\lambda_1 = 3\) : \(A – 3I_2 = \begin{pmatrix} 0 & 1 \\ 0 & -1 \end{pmatrix}\). Le noyau est \(E_3 = \mathrm{Vect}\begin{pmatrix} 1 \\ 0 \end{pmatrix}\).
Pour \(\lambda_2 = 2\) : \(A – 2I_2 = \begin{pmatrix} 1 & 1 \\ 0 & 0 \end{pmatrix}\). Le noyau est \(E_2 = \mathrm{Vect}\begin{pmatrix} -1 \\ 1 \end{pmatrix}\).
Étape 4 — Matrice de passage et diagonale.
\(P = \begin{pmatrix} 1 & -1 \\ 0 & 1 \end{pmatrix}, \quad D = \begin{pmatrix} 3 & 0 \\ 0 & 2 \end{pmatrix}\) \(P^{-1} = \begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix}\)Étape 5 — Calcul de \(A^n\).
\(A^n = P D^n P^{-1} = \begin{pmatrix} 1 & -1 \\ 0 & 1 \end{pmatrix} \begin{pmatrix} 3^n & 0 \\ 0 & 2^n \end{pmatrix} \begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix}\) \(= \begin{pmatrix} 3^n & -2^n \\ 0 & 2^n \end{pmatrix} \begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix} = \begin{pmatrix} 3^n & 3^n – 2^n \\ 0 & 2^n \end{pmatrix}\)Vérification pour \(n = 1\) : \(A^1 = \begin{pmatrix} 3 & 3-2 \\ 0 & 2 \end{pmatrix} = \begin{pmatrix} 3 & 1 \\ 0 & 2 \end{pmatrix} = A \quad \text{✓}\)
Exercice 6 ★★★ — Matrice nilpotente et binôme de Newton 🔴 Concours
Soit \(A = \begin{pmatrix} 1 & 1 & 0 \\ 0 & 1 & 1 \\ 0 & 0 & 1 \end{pmatrix}\). Poser \(N = A – I_3\).
- Calculer \(N^2\) et \(N^3\). En déduire que \(N\) est nilpotente.
- En utilisant le binôme de Newton matriciel, exprimer \(A^n\) pour tout \(n \in \mathbb{N}\).
Voir la correction
1. Nilpotence de \(N\).
\(N = A – I_3 = \begin{pmatrix} 0 & 1 & 0 \\ 0 & 0 & 1 \\ 0 & 0 & 0 \end{pmatrix}\) \(N^2 = N \times N = \begin{pmatrix} 0 & 0 & 1 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{pmatrix}\) \(N^3 = N^2 \times N = \begin{pmatrix} 0 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{pmatrix} = 0_3\)Conclusion : \(N\) est nilpotente d’indice 3. Pour tout \(k \geq 3\), \(N^k = 0\).
2. Calcul de \(A^n\) par le binôme de Newton.
On écrit \(A = I_3 + N\). Comme \(I_3\) et \(N\) commutent, le binôme de Newton s’applique :
\(A^n = (I_3 + N)^n = \sum_{k=0}^{n} \binom{n}{k} N^k\)Comme \(N^k = 0\) pour \(k \geq 3\), la somme se réduit (pour \(n \geq 2\)) à :
\(A^n = I_3 + nN + \binom{n}{2} N^2 = \begin{pmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{pmatrix} + n \begin{pmatrix} 0 & 1 & 0 \\ 0 & 0 & 1 \\ 0 & 0 & 0 \end{pmatrix} + \displaystyle\frac{n(n-1)}{2} \begin{pmatrix} 0 & 0 & 1 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{pmatrix}\) \(\fbox{A^n = \begin{pmatrix} 1 & n & \displaystyle\frac{n(n-1)}{2} \\ 0 & 1 & n \\ 0 & 0 & 1 \end{pmatrix}}\)Vérification : pour \(n = 1\), on retrouve \(A^1 = \begin{pmatrix} 1 & 1 & 0 \\ 0 & 1 & 1 \\ 0 & 0 & 1 \end{pmatrix} = A \quad \text{✓}\)
Remarque pour le concours. Ce type d’exercice est un classique absolu (X, Mines-Ponts, Centrale). Le schéma à retenir : décomposer \(A = I + N\) avec \(N\) nilpotente, puis appliquer le binôme de Newton en exploitant \(N^k = 0\) à partir d’un certain rang.
VI. Erreurs fréquentes et pièges classiques
Ces erreurs sont celles que les correcteurs de concours et de DS repèrent le plus souvent. Les connaître, c’est les éviter.
Piège 1 — « Le produit est commutatif »
❌ Copie fautive : « On a \(AB = BA\), donc… »
🔍 Diagnostic : le produit matriciel n’est pas commutatif. Affirmer \(AB = BA\) sans justification est une faute grave.
✅ Correction : toujours vérifier si les matrices commutent. Si l’énoncé ne le précise pas, on ne peut pas permuter. Les cas où \(AB = BA\) sont rares (matrices diagonales, polynômes d’une même matrice, etc.).
Piège 2 — « \(AB = 0\) donc \(A = 0\) ou \(B = 0\) »
❌ Copie fautive : « Comme \(AB = 0\), on en déduit que \(A = 0\) ou \(B = 0\). »
🔍 Diagnostic : cette règle est valable pour les réels, pas pour les matrices. Il existe des diviseurs de zéro dans \(\mathcal{M}_n(\mathbb{K})\).
✅ Contre-exemple : \(\begin{pmatrix} 1 & 0 \\ 0 & 0 \end{pmatrix} \begin{pmatrix} 0 & 0 \\ 0 & 1 \end{pmatrix} = \begin{pmatrix} 0 & 0 \\ 0 & 0 \end{pmatrix}\), pourtant aucune des deux matrices n’est nulle.
Piège 3 — Déterminant de la somme
❌ Copie fautive : « \(\det(A + B) = \det(A) + \det(B)\) »
🔍 Diagnostic : le déterminant est multiplicatif (\(\det(AB) = \det(A)\det(B)\)), pas additif.
✅ Rappel : il n’existe aucune formule simple pour \(\det(A + B)\) en fonction de \(\det(A)\) et \(\det(B)\).
Piège 4 — Transposée du produit : oublier d’inverser l’ordre
❌ Copie fautive : « \((AB)^T = A^T B^T\) »
✅ Formule correcte : \((AB)^T = B^T A^T\). L’ordre s’inverse. Même règle pour l’inverse : \((AB)^{-1} = B^{-1} A^{-1}\).
Piège 5 — Tailles incompatibles pour le produit
❌ Copie fautive : on calcule \(AB\) avec \(A \in \mathcal{M}_{2,3}\) et \(B \in \mathcal{M}_{2,3}\).
✅ Rappel : le produit \(AB\) n’est défini que si le nombre de colonnes de \(A\) est égal au nombre de lignes de \(B\). Ici, 3 colonnes pour \(A\) mais 2 lignes pour \(B\) : le produit n’existe pas.
VII. Questions fréquentes
Qu'est-ce qu'une matrice en mathématiques ?
Une matrice est un tableau rectangulaire de nombres (réels ou complexes), organisé en lignes et en colonnes. On la note \(A = (a_{i,j})\) où \(a_{i,j}\) est le coefficient situé à la ligne \(i\) et à la colonne \(j\). L’ensemble des matrices à \(m\) lignes et \(n\) colonnes est noté \(\mathcal{M}_{m,n}(\mathbb{K})\). Les matrices servent à représenter des systèmes d’équations linéaires, des transformations géométriques et des applications linéaires entre espaces vectoriels.
À quoi servent les matrices dans la vie réelle ?
Les matrices interviennent partout où des relations linéaires entre grandeurs sont en jeu : en informatique graphique (transformations 3D dans les jeux vidéo), en cryptographie (chiffrement de Hill), en machine learning (matrices de poids des réseaux de neurones), en physique quantique (opérateurs, matrices densité), en économie (modèle de Leontief, chaînes de Markov), en traitement du signal et en analyse de données (analyse en composantes principales). C’est l’un des outils mathématiques les plus utilisés dans les sciences appliquées.
Comment multiplier deux matrices ?
Le produit de \(A \in \mathcal{M}_{m,n}\) par \(B \in \mathcal{M}_{n,p}\) donne une matrice \(C \in \mathcal{M}_{m,p}\) dont le coefficient \(c_{i,j}\) est la somme des produits terme à terme de la ligne \(i\) de \(A\) par la colonne \(j\) de \(B\) : \(c_{i,j} = \sum_{k=1}^{n} a_{i,k} b_{k,j}\). Le nombre de colonnes de \(A\) doit être égal au nombre de lignes de \(B\). Consulte la page multiplication de matrices pour des exemples détaillés.
Quelle est la formule de l'inverse d'une matrice 2×2 ?
Pour \(A = \begin{pmatrix} a & b \\ c & d \end{pmatrix}\) avec \(\det(A) = ad – bc \neq 0\), l’inverse est : \(A^{-1} = \displaystyle\frac{1}{ad – bc} \begin{pmatrix} d & -b \\ -c & a \end{pmatrix}\). On permute les éléments diagonaux, on change le signe des éléments anti-diagonaux, et on divise par le déterminant. Voir la page inverse d’une matrice 2×2 pour plus d’exemples.
Comment savoir si une matrice est inversible ?
Une matrice carrée \(A \in \mathcal{M}_n(\mathbb{K})\) est inversible si et seulement si son déterminant est non nul : \(\det(A) \neq 0\). Cela équivaut à dire que son rang est maximal (\(\mathrm{rg}(A) = n\)), que son noyau est trivial (\(\ker(A) = \{0\}\)), ou que ses colonnes forment une famille libre. Voir la page matrice inversible : critères et déterminant.
Quelle est la différence entre une matrice et un déterminant ?
Une matrice est un tableau de nombres (un objet de \(\mathcal{M}_n(\mathbb{K})\)), tandis qu’un déterminant est un scalaire (un nombre dans \(\mathbb{K}\)) calculé à partir d’une matrice carrée. Le déterminant est une fonction qui prend une matrice en entrée et renvoie un nombre : \(\det : \mathcal{M}_n(\mathbb{K}) \to \mathbb{K}\). Confondre les deux est une erreur conceptuelle fréquente. Voir la page déterminant d’une matrice.
Quelles sont les principales règles du calcul matriciel ?
Les règles essentielles sont : (1) l’addition est définie uniquement entre matrices de même taille ; (2) le produit \(AB\) n’est défini que si le nombre de colonnes de \(A\) égale le nombre de lignes de \(B\) ; (3) le produit est associatif et distributif mais pas commutatif ; (4) \(\det(AB) = \det(A)\det(B)\) (multiplicativité) ; (5) \((AB)^T = B^T A^T\) et \((AB)^{-1} = B^{-1}A^{-1}\) (inversion de l’ordre).
Quel est le rang d'une matrice 3×3 dont les lignes sont (1,2,3), (4,5,6), (7,8,9) ?
Son rang est 2. En effet, la troisième ligne est la somme des deux autres (\(L_3 = 2L_2 – L_1\)), donc les trois lignes ne sont pas indépendantes. En échelonnant par la méthode de Gauss, on obtient exactement 2 pivots non nuls. Le déterminant de cette matrice est nul (\(\det = 0\)), ce qui confirme que le rang est strictement inférieur à 3. Voir la page rang d’une matrice pour la méthode complète.




